# How to Read CSV File in Bash
The file represents data in a plain text format, where each row is a record and columns are separated by commas. Since CSV files are simple and compatible, they are used across various applications, programming languages, and platforms. In this tutorial, we’ll learn how to parse values from Comma-Separated Values (CSV) file in Bash.
## Bash: Reading CSV File
There are two popular ways. Either using a loop to process each line or using the IFS (Internal Field Separator) to separate fields in the CSV file and store them in an array. By mastering these techniques, you will become adept at reading and processing CSV files efficiently using Bash.
### with a Loop
One of the methods for reading a CSV file is by using a loop. This method is very simple, using a while loop to iterate through each line of the CSV file and store them in an array.
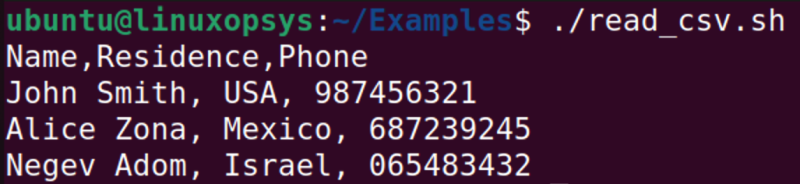
Let us use the following CSV file named “sample.csv”.
```
Name, Residence, Phone
John Smith, USA, 987456321
Alice Zona, Mexico, 687239245
Negev Adom, Israel, 065483432
```
Now, we should write a Bash script with a loop that allows us to store each line of the file in an array.
| `#!/bin/bash` `# Creation of variable containing the filenameFILE="sample.csv"` `# Creation of the empty arrayARRAY=()` `# Definition of the while loop to read a CSV file (by default:line-by-line)while` `read` `-r line; do # To append a line to the array ARRAY+=("$line") # The end of the loop, redirection of the content of FILE done` `< "$FILE"` `# Definition of the for loop to print out the content of ARRAY for` `line in` `"${ARRAY[@]}"; do` `# To print out the content of the line echo` `"$line"` `done` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### with IFS
IFS stands for Internal Field Separator, which is a special variable in Bash scripting which splits a string into an array based on a specific delimiter. When we use IFS, we can interact with a separate value within each line. It is a main difference between these two methods of processing a CSV file. This approach is useful when we want to access specific values within each CSV file line.
Now, we will consider the example of the Bash script that uses IFS:
| `#!/bin/bash` `# Creation of variable containing the filename FILE="sample.scv"` `# Creation of the empty array ARRAY=()` `# Definition of the while loop to read a CSV file (delimiter is comma) while` `IFS=, read` `-ra line; do ARRAY+=("$line")done` `< "$FILE"` `for` `record in` `"${ARRAY[@]}"; do echo` `"$record"done` |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
This bash script is almost the same as the previous one, but as you can see, IFS environmental variable with a value comma was added.
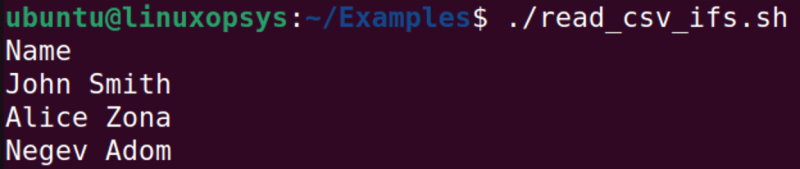
The read command read the input till it reaches the comma separator, so the second loop prints out all values that are in the first column. If we want to extract the whole line, then we can remove the comma.
| `while` `IFS= read` `-ra line; do ARRAY+=("$line")done` `< "$FILE”` |
| ------------------------------------------------------------------------- |
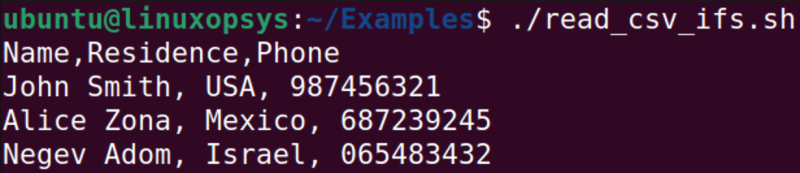
And we get again the output like it was without IFS.
The loop method is straightforward and allows us to store each line of the file in an array, whereas the IFS method provides more flexibility by allowing us to interact with individual values within each line, based on a specific delimiter.
#### Example 2
Let's look into a Bash script that can help to read CSV files containing server data into arrays.
The CSV file contains the following server metrics:
```
Timestamp,CPU Usage,Memory Usage,Disk Usage
2023-04-12T10:00:00,25,45,60
2023-04-12T10:05:00,30,50,65
2023-04-12T10:10:00,28,47,63
2023-04-12T10:15:00,32,52,68
2023-04-12T10:20:00,24,44,59
2023-04-12T10:25:00,26,46,61
```
| `#!/bin/bash` `# Declare an associative array to store server metricsdeclare` `-A server_metrics` `# Read the CSV file line by linewhile` `IFS=, read` `-r timestamp cpu_usage memory_usage disk_usage; do # Skip the header line if` `[[ "$timestamp"` `!= "Timestamp"` `]]; then # Store the metrics in the associative array using the timestamp as the key server_metrics["$timestamp"]="CPU: $cpu_usage%, Memory: $memory_usage%, Disk: $disk_usage%"` `fidone` `< server_metrics.csv` `# Print the server metricsfor` `key in` `"${!server_metrics[@]}"; do echo` `"Timestamp: $key, Metrics: ${server_metrics[$key]}"done` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
#### Handling Special Characters
Special characters (commas, quotes, newlines) can cause different issues during working with CVS files. To correctly read and process these files, we need to handle these special characters properly.
Now, we consider two other approaches to handling special characters. For instance, we have the following CSV file:
```
Name, Residence, Phone
"John Smith", "USA", 987456321
"Alice Zona", "Mexico", 687239245
"Negev Adom", "Israel", 065483432
```
To remove double quotes in my output, we may utilize two text processing tools sed or awk.
Added one sed command to the script that removes the double quotes from the output.
| `#!/bin/bash` `FILE="sample.csv"` `ARRAY=()` `while` `read` `-r line; do # it allows me to format a line, in this case to replace # by empty space line=$(echo` `"$line"` `\| sed` `'s/"//g') ARRAY+=("$line")done` `< "$FILE"` `for` `line in` `"${ARRAY[@]}"; do echo` `"$line"done` |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
After adding the 8th line, the output looks the following way:
In the following script, we have used the awk command to remove double quotes.
| `#!/bin/bash` `FILE="input.csv"` `ARRAY=()` `# the second way to replace " by empty spaceawk` `'{ gsub(/"/, ""); print }'` `sample.csv > $FILE` `while` `read` `-r line; do ARRAY+=("$line")done` `< "$FILE"` `for` `line in` `"${ARRAY[@]}"; do echo` `"$line"done` |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### Read specific columns
This section will consider how it is possible to handle columns when reading CSV files. Working with columns in CSV files is one of the common tasks during processing data and a comprehensive understanding of how to manipulate and extract specific columns is important.
The cut command is a utility that can be used to select specific columns from a CSV file. It reaches out via a delimiter and a list of field numbers. Here’s an example:
```
sample.csv
Name,Residence,Phone
John Smith, USA, 987456321
Alice Zona, Mexico, 687239245
Negev Adom, Israel, 065483432
```
For instance, it is necessary to extract the first column, then the script should look the following way:
| `#!/bin/bash` `FILE="sample.csv"` `while` `read` `-r line; do fst=$(echo` `"$line"` `\| cut` `-d ','` `-f 1) echo` `"$fst"done` `< "$FILE"` |
| --------------------------------------------------------------------------------------------------------------------------------------------------------- |
The script above is flexible since it allows to extract different columns from the file, in order to get, for example, the last 2 columns, then just to change the value denoted columns.
| `#!/bin/bash` `FILE="sample.csv"` `while` `read` `-r line; do fst=$(echo` `"$line"` `\| cut` `-d ','` `-f 2,3) echo` `"$fst"done` `< "$FILE"` |
| ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
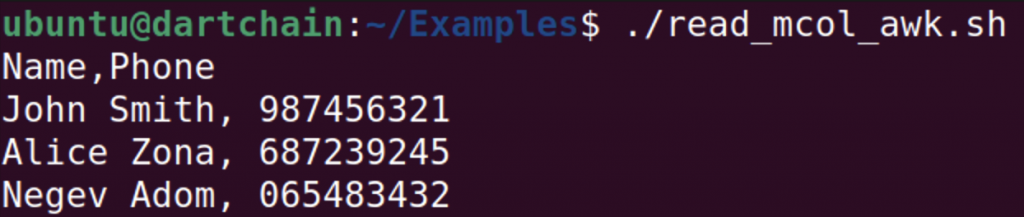
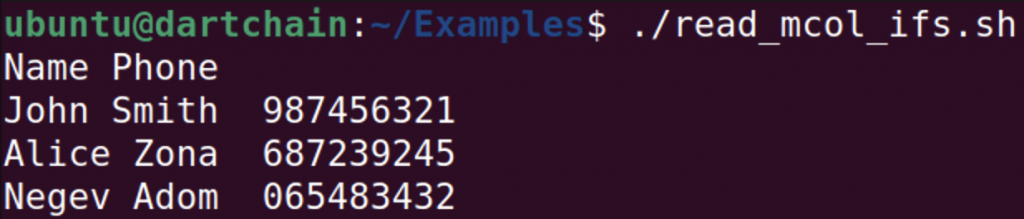
Let’s suppose there is a task to extract the column with names and phones. Fortunately, awk is a powerful text-processing tool that is able to solve the challenge, the script will be such:
| `#!/bin/bash` `FILE="sample.csv"` `while` `read` `-r line; do fst=$(echo` `"$line"` `\| awk` `-F ','` `'{ print $1 "," $3 }') echo` `"$fst"done` `< "$FILE"` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
Another method, possibly, is the simplest way since it is straightforward and does not require specific syntax.
| `#!/bin/bash` `FILE="sample.csv"` `while` `IFS=, read` `-r name residence phone ; do echo` `"$name"` `"$phone"done` `< "$FILE"` |
| -------------------------------------------------------------------------------------------------------------------------------------- |
In this example, also the task was to extract the columns name and phone. It was specified delimiter comma in IFS variable and listed all columns from the file.
As you see, the result is correct, the script extracted specified columns.
### Conclusion
* There are two methods of processing CSV files: using a loop or using IFS (Internal Filed Separator)
* A loop approach is straightforward allowing to store whole line.
* An IFS approach helps to work with each value within a line separately.
* There are tools to handle different special characters that it grants an opportunity to process files more flexibly.
* The provided example described the real-world application of Bash scripts relative to CSV files.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://morgan-bin-bash.gitbook.io/bash-scripting/how-to-read-csv-file-in-bash.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.